카프카는 어떻게 빠른 속도를 보이는 것인가?
디스크 기반의 저장소를 사용하는 카프카는 메모리 기반의 저장소를 사용하는 레디스보다도 더 좋은 성능을 보인다.
(memory 처리속도와 SSD 처리속도는 아래의 그림을 참고하면 된다.)
요약하면 "120 나노 세컨드"와 "50~150의 마이크로 세컨드"의 차이다.
(어마어마한 차이인 것이다.)
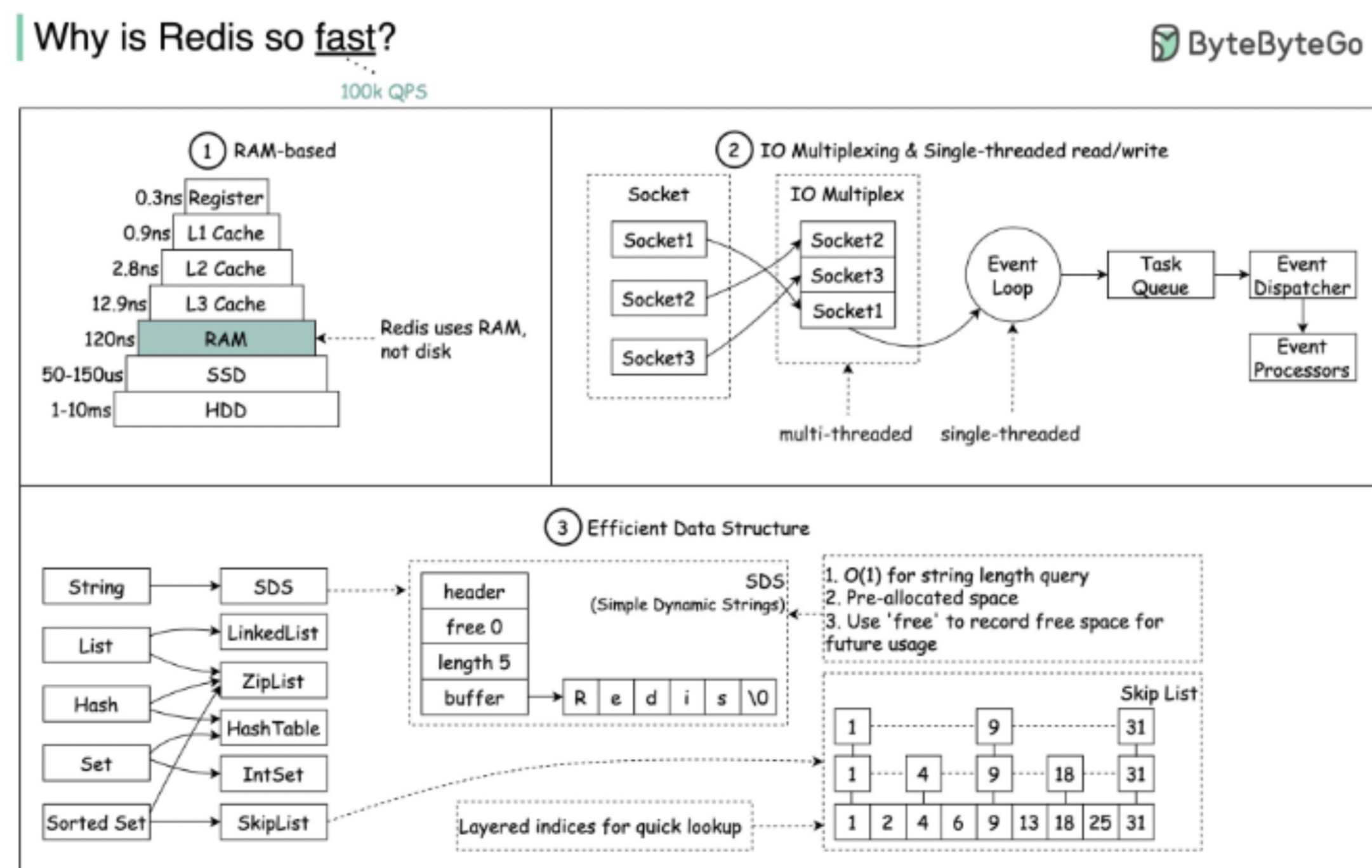
그럼 카프카는 어떻게 memory 기반의 redis를 MQ로써 사용할 때 보다 더 빠른 성능을 보이는 것인가?
그건 바로 저장소는 disk 기반으로 작동하지만, disk 에 저장하기전에 memory buffer pool에 batch 형식을 기반으로 동작한다는 것이다.
Producer 에서 메시지 이벤트를 발생시켜, 카프카 브로커로 전달될 때 로직레벨에서 이를 바로 디스크로 저장하지 않고,
할당된 여유공간을 이용 메모리 버퍼를 사용하여(별도 config 없으면 default value 로 할당) 주기적으로 disk 에 저장 시키고
또 내부 socket 통신을 이용해서 consumer 에서 data를 가져올 때에도 동일한 메카니즘으로 작동하는 것이다.
Producer 에 대한 자세한 config 설정은 하기 공식 kafka 사이트를 참고하기 바란다.
https://kafka.apache.org/documentation.html#producerapi
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
'AMQP > Kafka' 카테고리의 다른 글
| Kafka DLT 활용해서 재시도 처리 /w Spring (0) | 2025.05.05 |
|---|---|
| KRaft 사용하여 Kafka 컨테이너 띄우기 (0) | 2025.03.07 |
| Kafka 세팅 시 참고할 만한 내용정리 (1) | 2024.10.01 |
| Kafka 세팅 docker compose yaml (2) | 2024.09.12 |
