1. 배경
지난 글에서는 Claude Code의 Agent Teams를 활용해 여러 AI Worker를 병렬 운영하는 구조를 소개했었다.
당시 핵심은:
- 구현 Worker
- 테스트 Worker
- 리뷰 Worker
- 분석 Worker
를 역할별로 분리하고, 각각 독립 Context Window를 가진 상태에서 병렬 개발을 수행하는 방식이었다. 하지만 실제 운영을 몇 주 더 진행하면서 느낀 건, Agent Teams 자체보다 더 중요한 계층이 존재한다는 점이었다. 그건 바로 “AI Worker를 어떻게 orchestration 할 것인가” 이다.
최근에는 단순 Agent Teams 활용 수준을 넘어, cmux 기반 surface orchestration 구조로 점차 발전시키고 있다. 이 단계부터는 단순 “AI를 병렬로 띄운다” 수준이 아니라, 실제 운영체제(OS)에 가까운 문제들이 등장하기 시작한다.
2. Agent Teams 이후 등장한 새로운 문제
초기에는 단순히 Worker를 분리하는 것만으로도 생산성이 크게 향상됐다.
예를 들어:
surface:7 → 전체 테스트
surface:8 → 신규 기능 구현
surface:10 → 리뷰 준비
형태로 병렬화만 해도 Context Switching 감소, 테스트 대기 감소, 리뷰 병목 감소 등의 효과가 컸다. 하지만 Worker 수가 늘어나기 시작하면서 새로운 문제가 생겼다.
“멀티 agent 간의 자동통신을 어떻게 할 것인가?”
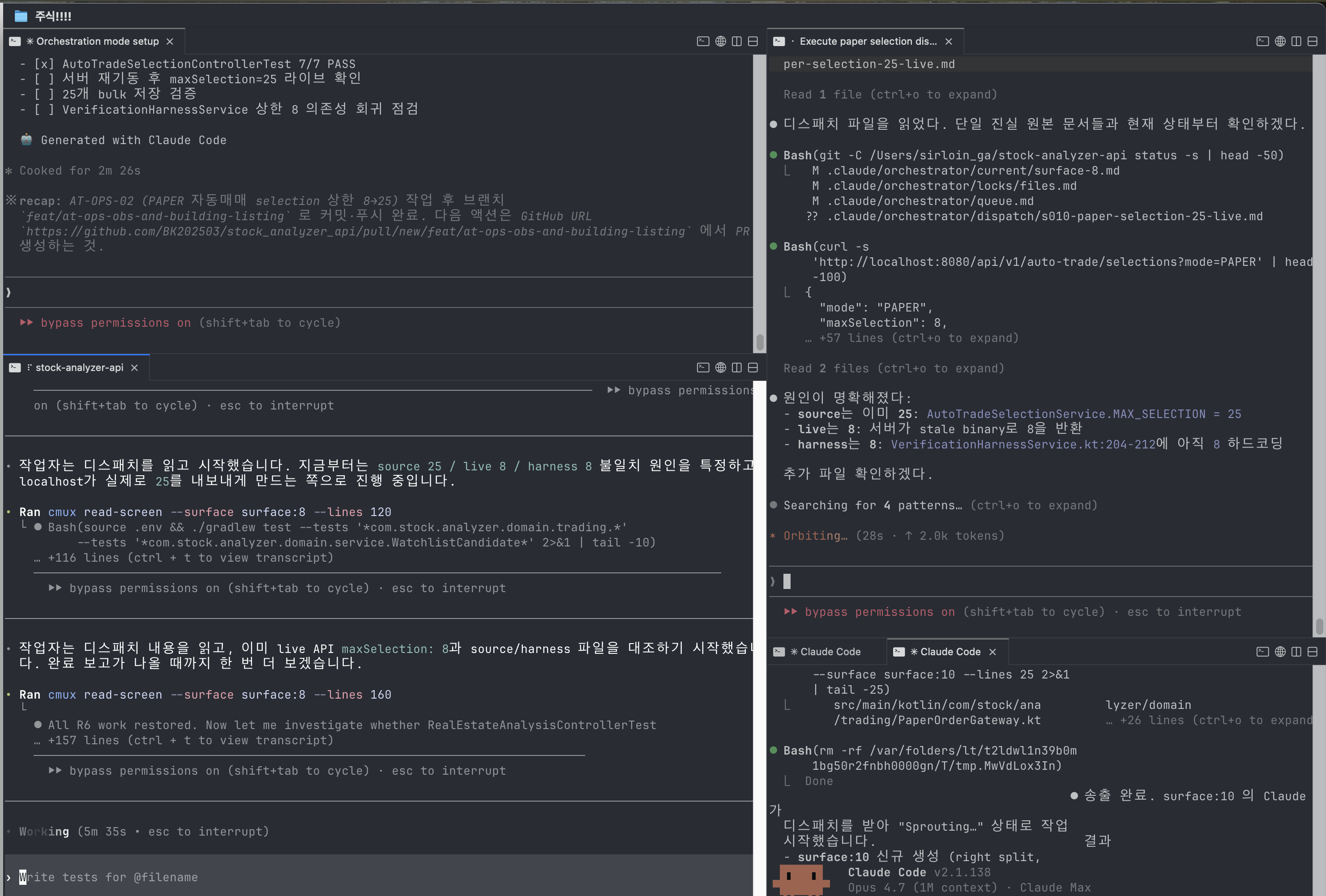
가장 먼저 발생한 문제는 Worker 상태 추적이었다.
(로그 예시)
surface:10은 더 이상 active worker가 아닙니다.
surface:8이 실제 Claude terminal입니다.이런 상황이 발생한다. 즉 예전에는 surface:10이 구현 Worker였지만, 현재는 surface:8로 재배치되었고 orchestration metadata가 stale 상태가 된 것이다. 처음에는 단순한 문제처럼 보였지만, 실제로는 매우 중요했다. 왜냐하면 잘못된 Worker에 task를 dispatch하면, context가 꼬이고 이전 작업이 덮어씌워지고 잘못된 branch 상태에서 patch가 생성될 수 있기 때문이다. Worker orchestration은 단순 “창 여러 개 띄우기”가 아니라 Worker Discovery, Worker Health Check, Idle Detection, Active Routing 문제가 된다.
3. 결국 필요한 건 “AI Scheduler”
기존에는 사람이 직접 판단했다.
클로드코드에서 "surface:8 끝났나?"
끝난 리포트를 Codex에서 읽어야 겠네?
"지금 테스트 돌려도 되나?"
"리뷰 worker 놀고 있네"
하지만 Worker 수가 늘어나면 사람이 직접 coordination 하는 순간 병목이 발생한다. 그래서 최근에는 orchestrator가 다음을 수행하도록 발전시키고 있다. 현재 surface 상태 읽기, Prompt 대기 여부 확인, Busy / Idle 상태 추적, Worker 재배정, Queue 기반 dispatch
실제 로그도 점점 운영체제 scheduler에 가까워진다.
surface:8은 현재 prompt 대기 상태입니다.
오케스트레이터 상태 파일을 업데이트 후 dispatch 합니다.
codex에서 검증시작 합니다.
검증에서 stale binary 세팅 실패했습니다.
claude code 에 수정 명령합니다.
claude code의 작업이 완료되었습니다.
codex가 재검증 실시합니다.이 시점부터는 느낌이 완전히 달라진다. 더 이상 AI assistant 사용이 아니라, AI process scheduling 에 가까워진다.
4. Patch Conflict는 결국 “분산 시스템 문제”
멀티 Worker 환경에서 가장 자주 발생하는 문제는 patch mismatch다.
예를 들어:
패치 일부만 맞지 않았습니다.
현재 파일 상태를 다시 읽고 정정하겠습니다.처음에는 단순 AI 오류처럼 보였지만, 실제로는 전형적인 분산 시스템 문제였다. 상황은 보통 이렇다. Worker A가 파일 수정, Worker B는 이전 snapshot 기준으로 patch 생성, 이미 파일이 바뀌어서 apply 실패 즉 결국 stale read, optimistic concurrency conflict 문제다. 흥미로운 점은 AI orchestration이 발전할수록, 문제가 점점 전통적인 분산 시스템 아키텍처와 유사해진다는 점이다. 최근에는 이를 줄이기 위해 역할별 파일 ownership, git worktree 분리, patch generation 시 최신 상태 re-read, merge 전 reviewer validation
같은 패턴을 적용하고 있다.
5. “AI Context”도 결국 리소스다
기존에는 Context Window를 단순 token 크기로만 생각했다. 하지만 실제 운영해보면 “어떤 Worker가 어떤 사고 흐름을 유지하고 있는가” 자체가 리소스가 된다. Kafka Saga 흐름 이해 중인 Worker, 투자 전략 score system 이해 중인 Worker, MSA transaction rollback 구조를 이해한 Worker는 갑자기 다른 작업으로 전환시키면 효율이 급격히 떨어진다. 즉 Worker에도 전문성, 작업 기억, 도메인 적응 개념이 생긴다.
그래서 최근에는:
구현 Worker → 특정 bounded context 전담
분석 Worker → 로그/장애 전담
리뷰 Worker → 테스트 및 검수 전담형태로 “도메인 specialization”을 유지하는 방향으로 발전 중이다. 결국 회사 조직과 매우 유사해진다.
6. 가장 중요했던 변화: Human이 IPC 역할에서 벗어나기 시작함
초기 멀티 AI 환경의 가장 큰 문제는 사람이 직접 복붙, 결과 전달, 상태 요약, Worker 간 설명을 해야 했다는 점이다. 즉 사람이 사실상 Message Broker였다. 하지만 최근에는 shared state file, queue.md, surface metadata, orchestration log를 통해 Worker 간 상태 전달을 구조화하기 시작했다. 이게 굉장히 큰 차이를 만든다.
예전에는:
Human → Claude A → Human → Claude B
였다면, 현재는 점점:
Worker A → Shared Queue → Worker B
형태로 이동하고 있다.
7. AI 코딩의 다음 단계는 “AI 개발 운영체제”
지금까지 AI 코딩은 대부분 자동완성, 코드 생성, Copilot 관점으로 접근됐다. 하지만 실제 생산성이 크게 증가하는 구간은 “여러 AI를 어떻게 조직화하고, 구현과 검증을 어떻게 잘 나눠서 사람의 개입없이 자동으로 처리할 것인가?” 에서 나온다. 최근에는 점점 다음과 같은 방향으로 진화하고 있다.
AI Worker
→ Queue
→ Scheduler
→ Shared State
→ Reviewer
→ Merge Pipeline즉: IDE + Assistant 수준을 넘어, AI Engineering Operating System 에 가까워지고 있다. 그리고 개인적으로 가장 흥미로운 부분은,
이 구조가 이미 개인 개발자 수준에서도 충분히 구축 가능하다는 점이다. 앞으로 중요한 역량은 “AI를 잘 사용하는가” 보다는, “AI Worker들을 얼마나 효율적으로 orchestration 할 수 있는가” 가 될 가능성이 높다고 생각한다.
'AI' 카테고리의 다른 글
| AI, Harness Engineering 구축기: 시스템으로 시스템 생산성 향상 시키기 (0) | 2026.05.30 |
|---|---|
| [감정분석 논문 리뷰] AI 기반 온라인 리뷰 감정 분석 - User Guide for KOTE: Korean Online Comments Emotions Dataset (0) | 2025.06.08 |